Batch effect correction (multiple batches)
Here we will use human pancreas datasets (scRNA-seq data) of different studies as an example to illustrate how Garfield performs scRNA-seq batch correction for multiple batches.
[1]:
import os
import pandas as pd
import numpy as np
os.chdir('/data2/zhouwg_data/project/Garfield')
os.getcwd()
[1]:
'/data2/zhouwg_data/project/Garfield'
[2]:
# load packages
import os
import warnings
import Garfield as gf
import scanpy as sc
warnings.simplefilter(action="ignore", category=FutureWarning)
warnings.simplefilter(action='ignore', category=UserWarning)
gf.__version__
[2]:
'1.0.0'
[3]:
## load data
adata = sc.read_h5ad('/home/zhouweige/zhouwg_data/project/Garfield_tutorials/data/panc8.h5ad')
adata
[3]:
AnnData object with n_obs × n_vars = 14890 × 34363
obs: 'ClusterID', 'ClusterName', 'batch', 'celltype', 'nCount_RNA'
var: 'Selected', 'vst_mean', 'vst_variable', 'vst_variance', 'vst_variance_expected', 'vst_variance_standardized'
obsm: 'pca_cell_embeddings', 'umap_cell_embeddings'
varm: 'pca_feature_loadings'
layers: 'counts', 'norm_data', 'scale_data'
[4]:
# Ensure adata.X is counts.
adata.X.max()
[4]:
1453667.0
[5]:
# check the batch information of this dataset
adata.obs['batch'].value_counts()
[5]:
batch
indrop 8569
smartseq2 2394
celseq2 2285
celseq 1004
fluidigmc1 638
Name: count, dtype: int64
Perform batch effect correction using Garfield
For batch effect correction from scRNAseq data, we should adjust the following paremeters, and all parameter introductions can be found in Garfield_Model_Parameters.
[6]:
# set workdir
workdir = '/home/zhouweige/zhouwg_data/project/Garfield_tutorials/result/garfield_scRNA_panc'
gf.settings.set_workdir(workdir)
### modify parameter
user_config = dict(
## Input options
adata_list=adata,
profile='RNA', # if it is 'ATAC' or 'ADT', please adjust it.
sample_col='batch', # Specify columns for batch information.
## Preprocessing options
used_hvg=True,
min_cells=3,
min_features=0,
keep_mt=False,
target_sum=1e4,
rna_n_top_features=3000,
atac_n_top_features=None, # if data belongs to 'ATAC', please specify it.
n_components=50,
n_neighbors=5,
metric='euclidean', # STR Metric for clustering. Default is `euclidean`.
svd_solver='arpack',
# datasets
used_pca_feat=False,
adj_key='connectivities',
# data split parameters
edge_val_ratio=0.1,
edge_test_ratio=0.,
node_val_ratio=0.1,
node_test_ratio=0.,
## Model options
augment_type='svd',
svd_q=5,
use_FCencoder=False,
conv_type='GATv2Conv', # GAT or GATv2Conv or GCN
gnn_layer=2,
hidden_dims=[128, 128],
bottle_neck_neurons=20,
cluster_num=20,
drop_feature_rate=0.2,
drop_edge_rate=0.2,
num_heads=3,
dropout=0.2,
concat=True,
used_edge_weight=False,
used_DSBN=False,
used_mmd=True,
# data loader parameters
num_neighbors=5,
loaders_n_hops=2,
edge_batch_size=4096,
node_batch_size=256, # None
# loss parameters
include_edge_recon_loss=False,
include_gene_expr_recon_loss=True,
lambda_latent_contrastive_instanceloss=1.0,
lambda_latent_contrastive_clusterloss=0.5,
lambda_gene_expr_recon=10., # To make the model more focused on learning expression features, increase this parameter.
lambda_edge_recon=1., # To make the model more focused on learning Adjacency graph features, increase this parameter.
lambda_latent_adj_recon_loss=1.0,
lambda_omics_recon_mmd_loss=5.0, # If the integration is not strong enough, increase it.
# train parameters
n_epochs_no_edge_recon=0,
learning_rate=0.001,
weight_decay=1e-05,
gradient_clipping=5,
# other parameters
latent_key='garfield_latent',
reload_best_model=True,
use_early_stopping=True,
early_stopping_kwargs=None,
monitor=True,
seed=42,
device_id=1, # GPU device id, default is 0.
verbose=True
)
dict_config = gf.settings.set_gf_params(user_config)
Saving results in: /home/zhouweige/zhouwg_data/project/Garfield_tutorials/result/garfield_scRNA_panc
[7]:
from Garfield.model import Garfield
# Initialize model
model = Garfield(dict_config)
--- DATA LOADING AND PREPROCESSING ---
/home/zhouweige/anaconda3/envs/Garfield/lib/python3.9/site-packages/scipy/sparse/_index.py:143: SparseEfficiencyWarning: Changing the sparsity structure of a csr_matrix is expensive. lil_matrix is more efficient.
self._set_arrayXarray(i, j, x)
COSINE SIM GRAPH DECODER -> dropout_rate: 0.2
[8]:
# Train model
model.train()
--- INITIALIZING TRAINER ---
Using GPU: device-1
Number of training nodes: 13401
Number of validation nodes: 1489
Number of training edges: 41925
Number of validation edges: 4658
Edge batch size: 4096
Node batch size: 256
--- MODEL TRAINING ---
Epoch 1/100 |--------------------| 1.0% val_auroc_score: 0.9093; val_auprc_score: 0.8986; val_best_acc_score: 0.8243; val_best_f1_score: 0.8329; train_kl_reg_loss: 8.7155; train_edge_recon_loss: 1065.0080; train_gene_expr_recon_loss: 44671.5746; train_lambda_latent_adj_recon_loss: 440.3092; train_lambda_latent_contrastive_instanceloss: 7.8564; train_lambda_latent_contrastive_clusterloss: 3.7105; train_gene_expr_mmd_loss: 14061.0143; train_global_loss: 59193.1797; train_optim_loss: 59193.1797; val_kl_reg_loss: 5.3916; val_edge_recon_loss: 688.0709; val_gene_expr_recon_loss: 37423.5762; val_lambda_latent_adj_recon_loss: 173.0055; val_lambda_latent_contrastive_instanceloss: 7.6594; val_lambda_latent_contrastive_clusterloss: 3.7370; val_gene_expr_mmd_loss: 21762.3564; val_global_loss: 59375.7227; val_optim_loss: 59375.7227
Epoch 2/100 |--------------------| 2.0% val_auroc_score: 0.9264; val_auprc_score: 0.9153; val_best_acc_score: 0.8451; val_best_f1_score: 0.8555; train_kl_reg_loss: 10.8722; train_edge_recon_loss: 1065.8328; train_gene_expr_recon_loss: 36582.6516; train_lambda_latent_adj_recon_loss: 401.8171; train_lambda_latent_contrastive_instanceloss: 7.8503; train_lambda_latent_contrastive_clusterloss: 3.6813; train_gene_expr_mmd_loss: 13492.7813; train_global_loss: 50499.6541; train_optim_loss: 50499.6541; val_kl_reg_loss: 13.1268; val_edge_recon_loss: 705.0635; val_gene_expr_recon_loss: 32057.1045; val_lambda_latent_adj_recon_loss: 350.7688; val_lambda_latent_contrastive_instanceloss: 7.6931; val_lambda_latent_contrastive_clusterloss: 3.6767; val_gene_expr_mmd_loss: 26613.6338; val_global_loss: 59046.0039; val_optim_loss: 59046.0039
Epoch 3/100 |--------------------| 3.0% val_auroc_score: 0.9356; val_auprc_score: 0.9234; val_best_acc_score: 0.8437; val_best_f1_score: 0.8554; train_kl_reg_loss: 15.1798; train_edge_recon_loss: 1061.9361; train_gene_expr_recon_loss: 32130.4002; train_lambda_latent_adj_recon_loss: 470.1426; train_lambda_latent_contrastive_instanceloss: 7.8198; train_lambda_latent_contrastive_clusterloss: 3.6628; train_gene_expr_mmd_loss: 13374.0771; train_global_loss: 46001.2827; train_optim_loss: 46001.2827; val_kl_reg_loss: 13.4782; val_edge_recon_loss: 704.8921; val_gene_expr_recon_loss: 28679.8516; val_lambda_latent_adj_recon_loss: 383.4118; val_lambda_latent_contrastive_instanceloss: 7.6227; val_lambda_latent_contrastive_clusterloss: 3.6494; val_gene_expr_mmd_loss: 25996.4844; val_global_loss: 55084.4961; val_optim_loss: 55084.4961
Epoch 4/100 |--------------------| 4.0% val_auroc_score: 0.9247; val_auprc_score: 0.9128; val_best_acc_score: 0.8349; val_best_f1_score: 0.8522; train_kl_reg_loss: 19.4460; train_edge_recon_loss: 1068.7067; train_gene_expr_recon_loss: 30072.1681; train_lambda_latent_adj_recon_loss: 591.8536; train_lambda_latent_contrastive_instanceloss: 7.8050; train_lambda_latent_contrastive_clusterloss: 3.6528; train_gene_expr_mmd_loss: 12567.2664; train_global_loss: 43262.1918; train_optim_loss: 43262.1918; val_kl_reg_loss: 16.3816; val_edge_recon_loss: 715.7468; val_gene_expr_recon_loss: 27819.5674; val_lambda_latent_adj_recon_loss: 468.3962; val_lambda_latent_contrastive_instanceloss: 7.5967; val_lambda_latent_contrastive_clusterloss: 3.6293; val_gene_expr_mmd_loss: 20474.0527; val_global_loss: 48789.6250; val_optim_loss: 48789.6250
Epoch 5/100 |█-------------------| 5.0% val_auroc_score: 0.9299; val_auprc_score: 0.9132; val_best_acc_score: 0.8354; val_best_f1_score: 0.8549; train_kl_reg_loss: 23.4726; train_edge_recon_loss: 1073.8238; train_gene_expr_recon_loss: 28880.2095; train_lambda_latent_adj_recon_loss: 691.7453; train_lambda_latent_contrastive_instanceloss: 7.7659; train_lambda_latent_contrastive_clusterloss: 3.6416; train_gene_expr_mmd_loss: 13418.6274; train_global_loss: 43025.4627; train_optim_loss: 43025.4627; val_kl_reg_loss: 20.5937; val_edge_recon_loss: 714.3441; val_gene_expr_recon_loss: 27987.6807; val_lambda_latent_adj_recon_loss: 561.1783; val_lambda_latent_contrastive_instanceloss: 7.4144; val_lambda_latent_contrastive_clusterloss: 3.5805; val_gene_expr_mmd_loss: 23386.4756; val_global_loss: 51966.9219; val_optim_loss: 51966.9219
Epoch 6/100 |█-------------------| 6.0% val_auroc_score: 0.9335; val_auprc_score: 0.9105; val_best_acc_score: 0.8257; val_best_f1_score: 0.8498; train_kl_reg_loss: 27.8729; train_edge_recon_loss: 1080.4548; train_gene_expr_recon_loss: 28220.5108; train_lambda_latent_adj_recon_loss: 778.2623; train_lambda_latent_contrastive_instanceloss: 7.7040; train_lambda_latent_contrastive_clusterloss: 3.6304; train_gene_expr_mmd_loss: 12186.6403; train_global_loss: 41224.6211; train_optim_loss: 41224.6211; val_kl_reg_loss: 24.5050; val_edge_recon_loss: 726.8703; val_gene_expr_recon_loss: 27626.7539; val_lambda_latent_adj_recon_loss: 640.9619; val_lambda_latent_contrastive_instanceloss: 7.3422; val_lambda_latent_contrastive_clusterloss: 3.5422; val_gene_expr_mmd_loss: 20154.2354; val_global_loss: 48457.3418; val_optim_loss: 48457.3418
Epoch 7/100 |█-------------------| 7.0% val_auroc_score: 0.9466; val_auprc_score: 0.9273; val_best_acc_score: 0.8709; val_best_f1_score: 0.8852; train_kl_reg_loss: 33.5212; train_edge_recon_loss: 1090.5873; train_gene_expr_recon_loss: 27786.5625; train_lambda_latent_adj_recon_loss: 916.5806; train_lambda_latent_contrastive_instanceloss: 7.6600; train_lambda_latent_contrastive_clusterloss: 3.6118; train_gene_expr_mmd_loss: 12452.2979; train_global_loss: 41200.2340; train_optim_loss: 41200.2340; val_kl_reg_loss: 29.9040; val_edge_recon_loss: 729.3929; val_gene_expr_recon_loss: 26073.2656; val_lambda_latent_adj_recon_loss: 733.6420; val_lambda_latent_contrastive_instanceloss: 7.3350; val_lambda_latent_contrastive_clusterloss: 3.4616; val_gene_expr_mmd_loss: 18381.7964; val_global_loss: 45229.4043; val_optim_loss: 45229.4043
Epoch 8/100 |█-------------------| 8.0% val_auroc_score: 0.9445; val_auprc_score: 0.9193; val_best_acc_score: 0.8841; val_best_f1_score: 0.8950; train_kl_reg_loss: 38.1084; train_edge_recon_loss: 1096.7893; train_gene_expr_recon_loss: 26852.3768; train_lambda_latent_adj_recon_loss: 1018.1229; train_lambda_latent_contrastive_instanceloss: 7.6482; train_lambda_latent_contrastive_clusterloss: 3.5907; train_gene_expr_mmd_loss: 11820.9081; train_global_loss: 39740.7553; train_optim_loss: 39740.7553; val_kl_reg_loss: 29.3636; val_edge_recon_loss: 724.0182; val_gene_expr_recon_loss: 25709.3682; val_lambda_latent_adj_recon_loss: 641.7983; val_lambda_latent_contrastive_instanceloss: 7.3162; val_lambda_latent_contrastive_clusterloss: 3.3972; val_gene_expr_mmd_loss: 21211.4629; val_global_loss: 47602.7051; val_optim_loss: 47602.7051
Epoch 9/100 |█-------------------| 9.0% val_auroc_score: 0.9367; val_auprc_score: 0.9160; val_best_acc_score: 0.8649; val_best_f1_score: 0.8797; train_kl_reg_loss: 36.9429; train_edge_recon_loss: 1093.1434; train_gene_expr_recon_loss: 26552.5938; train_lambda_latent_adj_recon_loss: 856.0561; train_lambda_latent_contrastive_instanceloss: 7.6319; train_lambda_latent_contrastive_clusterloss: 3.5641; train_gene_expr_mmd_loss: 10827.9786; train_global_loss: 38284.7670; train_optim_loss: 38284.7670; val_kl_reg_loss: 29.3621; val_edge_recon_loss: 724.9586; val_gene_expr_recon_loss: 25403.8311; val_lambda_latent_adj_recon_loss: 587.1233; val_lambda_latent_contrastive_instanceloss: 7.3033; val_lambda_latent_contrastive_clusterloss: 3.3148; val_gene_expr_mmd_loss: 17579.6777; val_global_loss: 43610.6133; val_optim_loss: 43610.6133
Epoch 10/100 |██------------------| 10.0% val_auroc_score: 0.9451; val_auprc_score: 0.9259; val_best_acc_score: 0.8695; val_best_f1_score: 0.8837; train_kl_reg_loss: 37.5784; train_edge_recon_loss: 1091.9021; train_gene_expr_recon_loss: 26177.9490; train_lambda_latent_adj_recon_loss: 773.5619; train_lambda_latent_contrastive_instanceloss: 7.6196; train_lambda_latent_contrastive_clusterloss: 3.5406; train_gene_expr_mmd_loss: 12107.8724; train_global_loss: 39108.1225; train_optim_loss: 39108.1225; val_kl_reg_loss: 33.4987; val_edge_recon_loss: 729.2998; val_gene_expr_recon_loss: 25595.7373; val_lambda_latent_adj_recon_loss: 629.8362; val_lambda_latent_contrastive_instanceloss: 7.2433; val_lambda_latent_contrastive_clusterloss: 3.2442; val_gene_expr_mmd_loss: 23270.7354; val_global_loss: 49540.2949; val_optim_loss: 49540.2949
Epoch 11/100 |██------------------| 11.0% val_auroc_score: 0.9487; val_auprc_score: 0.9316; val_best_acc_score: 0.8752; val_best_f1_score: 0.8880; train_kl_reg_loss: 38.6455; train_edge_recon_loss: 1094.0858; train_gene_expr_recon_loss: 26135.3008; train_lambda_latent_adj_recon_loss: 732.2823; train_lambda_latent_contrastive_instanceloss: 7.5893; train_lambda_latent_contrastive_clusterloss: 3.5054; train_gene_expr_mmd_loss: 11113.8084; train_global_loss: 38031.1317; train_optim_loss: 38031.1317; val_kl_reg_loss: 31.1830; val_edge_recon_loss: 728.7766; val_gene_expr_recon_loss: 24723.6025; val_lambda_latent_adj_recon_loss: 512.9958; val_lambda_latent_contrastive_instanceloss: 7.2731; val_lambda_latent_contrastive_clusterloss: 3.2157; val_gene_expr_mmd_loss: 17841.3936; val_global_loss: 43119.6621; val_optim_loss: 43119.6621
Epoch 12/100 |██------------------| 12.0% val_auroc_score: 0.9362; val_auprc_score: 0.9130; val_best_acc_score: 0.8431; val_best_f1_score: 0.8637; train_kl_reg_loss: 43.1072; train_edge_recon_loss: 1100.8644; train_gene_expr_recon_loss: 26028.4276; train_lambda_latent_adj_recon_loss: 773.2272; train_lambda_latent_contrastive_instanceloss: 7.5752; train_lambda_latent_contrastive_clusterloss: 3.4694; train_gene_expr_mmd_loss: 10332.8816; train_global_loss: 37188.6882; train_optim_loss: 37188.6882; val_kl_reg_loss: 39.0567; val_edge_recon_loss: 733.8325; val_gene_expr_recon_loss: 25807.2637; val_lambda_latent_adj_recon_loss: 645.6829; val_lambda_latent_contrastive_instanceloss: 7.2126; val_lambda_latent_contrastive_clusterloss: 3.1383; val_gene_expr_mmd_loss: 18187.6816; val_global_loss: 44690.0352; val_optim_loss: 44690.0352
Epoch 13/100 |██------------------| 13.0% val_auroc_score: 0.9310; val_auprc_score: 0.9032; val_best_acc_score: 0.8372; val_best_f1_score: 0.8594; train_kl_reg_loss: 49.6764; train_edge_recon_loss: 1111.0325; train_gene_expr_recon_loss: 25630.7619; train_lambda_latent_adj_recon_loss: 882.5638; train_lambda_latent_contrastive_instanceloss: 7.5408; train_lambda_latent_contrastive_clusterloss: 3.4050; train_gene_expr_mmd_loss: 11006.4680; train_global_loss: 37580.4162; train_optim_loss: 37580.4162; val_kl_reg_loss: 44.9656; val_edge_recon_loss: 738.2226; val_gene_expr_recon_loss: 25203.5889; val_lambda_latent_adj_recon_loss: 707.5315; val_lambda_latent_contrastive_instanceloss: 7.2563; val_lambda_latent_contrastive_clusterloss: 3.1052; val_gene_expr_mmd_loss: 16606.3931; val_global_loss: 42572.8398; val_optim_loss: 42572.8398
Epoch 14/100 |██------------------| 14.0% val_auroc_score: 0.9322; val_auprc_score: 0.9099; val_best_acc_score: 0.8393; val_best_f1_score: 0.8608; train_kl_reg_loss: 53.1246; train_edge_recon_loss: 1113.7830; train_gene_expr_recon_loss: 25888.1230; train_lambda_latent_adj_recon_loss: 877.9505; train_lambda_latent_contrastive_instanceloss: 7.5129; train_lambda_latent_contrastive_clusterloss: 3.3606; train_gene_expr_mmd_loss: 9510.7462; train_global_loss: 36340.8171; train_optim_loss: 36340.8171; val_kl_reg_loss: 39.5459; val_edge_recon_loss: 736.0344; val_gene_expr_recon_loss: 25300.4912; val_lambda_latent_adj_recon_loss: 530.7840; val_lambda_latent_contrastive_instanceloss: 7.2108; val_lambda_latent_contrastive_clusterloss: 3.0406; val_gene_expr_mmd_loss: 16488.0278; val_global_loss: 42369.0996; val_optim_loss: 42369.0996
Epoch 15/100 |███-----------------| 15.0% val_auroc_score: 0.9456; val_auprc_score: 0.9298; val_best_acc_score: 0.8540; val_best_f1_score: 0.8718; train_kl_reg_loss: 50.4126; train_edge_recon_loss: 1109.3573; train_gene_expr_recon_loss: 25473.5863; train_lambda_latent_adj_recon_loss: 708.7039; train_lambda_latent_contrastive_instanceloss: 7.5353; train_lambda_latent_contrastive_clusterloss: 3.3467; train_gene_expr_mmd_loss: 9704.3569; train_global_loss: 35947.9414; train_optim_loss: 35947.9414; val_kl_reg_loss: 40.0924; val_edge_recon_loss: 736.8257; val_gene_expr_recon_loss: 24961.3086; val_lambda_latent_adj_recon_loss: 483.6541; val_lambda_latent_contrastive_instanceloss: 7.2102; val_lambda_latent_contrastive_clusterloss: 2.9867; val_gene_expr_mmd_loss: 19030.7705; val_global_loss: 44526.0234; val_optim_loss: 44526.0234
Epoch 16/100 |███-----------------| 16.0% val_auroc_score: 0.9324; val_auprc_score: 0.9055; val_best_acc_score: 0.8431; val_best_f1_score: 0.8634; train_kl_reg_loss: 54.3147; train_edge_recon_loss: 1115.4550; train_gene_expr_recon_loss: 25773.8766; train_lambda_latent_adj_recon_loss: 729.5426; train_lambda_latent_contrastive_instanceloss: 7.4988; train_lambda_latent_contrastive_clusterloss: 3.2819; train_gene_expr_mmd_loss: 11475.0345; train_global_loss: 38043.5497; train_optim_loss: 38043.5497; val_kl_reg_loss: 43.6515; val_edge_recon_loss: 737.1089; val_gene_expr_recon_loss: 25706.3418; val_lambda_latent_adj_recon_loss: 505.4907; val_lambda_latent_contrastive_instanceloss: 7.1550; val_lambda_latent_contrastive_clusterloss: 2.9230; val_gene_expr_mmd_loss: 17660.4834; val_global_loss: 43926.0469; val_optim_loss: 43926.0469
Epoch 17/100 |███-----------------| 17.0% val_auroc_score: 0.9447; val_auprc_score: 0.9257; val_best_acc_score: 0.8570; val_best_f1_score: 0.8742; train_kl_reg_loss: 54.8936; train_edge_recon_loss: 1114.9707; train_gene_expr_recon_loss: 25272.5080; train_lambda_latent_adj_recon_loss: 675.8816; train_lambda_latent_contrastive_instanceloss: 7.4974; train_lambda_latent_contrastive_clusterloss: 3.2498; train_gene_expr_mmd_loss: 9466.0551; train_global_loss: 35480.0852; train_optim_loss: 35480.0852; val_kl_reg_loss: 42.5129; val_edge_recon_loss: 737.3000; val_gene_expr_recon_loss: 25455.4775; val_lambda_latent_adj_recon_loss: 448.1633; val_lambda_latent_contrastive_instanceloss: 7.1749; val_lambda_latent_contrastive_clusterloss: 2.8840; val_gene_expr_mmd_loss: 20247.3447; val_global_loss: 46203.5566; val_optim_loss: 46203.5566
Epoch 18/100 |███-----------------| 18.0% val_auroc_score: 0.9419; val_auprc_score: 0.9201; val_best_acc_score: 0.8583; val_best_f1_score: 0.8751; train_kl_reg_loss: 56.1664; train_edge_recon_loss: 1114.8510; train_gene_expr_recon_loss: 25398.6751; train_lambda_latent_adj_recon_loss: 643.7251; train_lambda_latent_contrastive_instanceloss: 7.4749; train_lambda_latent_contrastive_clusterloss: 3.1961; train_gene_expr_mmd_loss: 9709.1822; train_global_loss: 35818.4205; train_optim_loss: 35818.4205; val_kl_reg_loss: 42.8394; val_edge_recon_loss: 736.0747; val_gene_expr_recon_loss: 25118.1689; val_lambda_latent_adj_recon_loss: 412.1299; val_lambda_latent_contrastive_instanceloss: 7.1688; val_lambda_latent_contrastive_clusterloss: 2.8523; val_gene_expr_mmd_loss: 18284.0107; val_global_loss: 43867.1680; val_optim_loss: 43867.1680
Reducing learning rate: metric has not improved more than 0.0 in the last 4 epochs.
New learning rate is 0.0001.
Epoch 19/100 |███-----------------| 19.0% val_auroc_score: 0.9406; val_auprc_score: 0.9196; val_best_acc_score: 0.8526; val_best_f1_score: 0.8708; train_kl_reg_loss: 58.4420; train_edge_recon_loss: 1116.3784; train_gene_expr_recon_loss: 25352.8404; train_lambda_latent_adj_recon_loss: 642.3280; train_lambda_latent_contrastive_instanceloss: 7.4729; train_lambda_latent_contrastive_clusterloss: 3.1566; train_gene_expr_mmd_loss: 10471.6390; train_global_loss: 36535.8793; train_optim_loss: 36535.8793; val_kl_reg_loss: 43.7232; val_edge_recon_loss: 737.2150; val_gene_expr_recon_loss: 24741.5791; val_lambda_latent_adj_recon_loss: 419.5482; val_lambda_latent_contrastive_instanceloss: 7.1688; val_lambda_latent_contrastive_clusterloss: 2.8555; val_gene_expr_mmd_loss: 18362.2603; val_global_loss: 43577.1328; val_optim_loss: 43577.1328
Epoch 20/100 |████----------------| 20.0% val_auroc_score: 0.9385; val_auprc_score: 0.9143; val_best_acc_score: 0.8380; val_best_f1_score: 0.8597; train_kl_reg_loss: 59.0152; train_edge_recon_loss: 1117.3935; train_gene_expr_recon_loss: 25213.5746; train_lambda_latent_adj_recon_loss: 651.0413; train_lambda_latent_contrastive_instanceloss: 7.4671; train_lambda_latent_contrastive_clusterloss: 3.1607; train_gene_expr_mmd_loss: 9636.1005; train_global_loss: 35570.3590; train_optim_loss: 35570.3590; val_kl_reg_loss: 44.3998; val_edge_recon_loss: 737.6171; val_gene_expr_recon_loss: 25276.5449; val_lambda_latent_adj_recon_loss: 426.9086; val_lambda_latent_contrastive_instanceloss: 7.1676; val_lambda_latent_contrastive_clusterloss: 2.8280; val_gene_expr_mmd_loss: 18481.2188; val_global_loss: 44239.0684; val_optim_loss: 44239.0684
Epoch 21/100 |████----------------| 21.0% val_auroc_score: 0.9390; val_auprc_score: 0.9110; val_best_acc_score: 0.8507; val_best_f1_score: 0.8693; train_kl_reg_loss: 59.6638; train_edge_recon_loss: 1117.7462; train_gene_expr_recon_loss: 25137.1135; train_lambda_latent_adj_recon_loss: 655.0555; train_lambda_latent_contrastive_instanceloss: 7.4574; train_lambda_latent_contrastive_clusterloss: 3.1470; train_gene_expr_mmd_loss: 9437.6299; train_global_loss: 35300.0678; train_optim_loss: 35300.0678; val_kl_reg_loss: 45.0702; val_edge_recon_loss: 737.8107; val_gene_expr_recon_loss: 24706.9014; val_lambda_latent_adj_recon_loss: 430.1380; val_lambda_latent_contrastive_instanceloss: 7.1545; val_lambda_latent_contrastive_clusterloss: 2.8288; val_gene_expr_mmd_loss: 14764.5215; val_global_loss: 39956.6133; val_optim_loss: 39956.6133
Epoch 22/100 |████----------------| 22.0% val_auroc_score: 0.9423; val_auprc_score: 0.9226; val_best_acc_score: 0.8446; val_best_f1_score: 0.8647; train_kl_reg_loss: 60.4198; train_edge_recon_loss: 1119.7007; train_gene_expr_recon_loss: 25098.6701; train_lambda_latent_adj_recon_loss: 662.2330; train_lambda_latent_contrastive_instanceloss: 7.4559; train_lambda_latent_contrastive_clusterloss: 3.1364; train_gene_expr_mmd_loss: 9339.4799; train_global_loss: 35171.3945; train_optim_loss: 35171.3945; val_kl_reg_loss: 45.4806; val_edge_recon_loss: 738.4477; val_gene_expr_recon_loss: 25044.4570; val_lambda_latent_adj_recon_loss: 434.5674; val_lambda_latent_contrastive_instanceloss: 7.1448; val_lambda_latent_contrastive_clusterloss: 2.8141; val_gene_expr_mmd_loss: 16251.4995; val_global_loss: 41785.9648; val_optim_loss: 41785.9648
Epoch 23/100 |████----------------| 23.0% val_auroc_score: 0.9404; val_auprc_score: 0.9193; val_best_acc_score: 0.8372; val_best_f1_score: 0.8592; train_kl_reg_loss: 61.1195; train_edge_recon_loss: 1120.3837; train_gene_expr_recon_loss: 25051.6325; train_lambda_latent_adj_recon_loss: 669.7311; train_lambda_latent_contrastive_instanceloss: 7.4432; train_lambda_latent_contrastive_clusterloss: 3.1295; train_gene_expr_mmd_loss: 9142.4275; train_global_loss: 34935.4830; train_optim_loss: 34935.4830; val_kl_reg_loss: 46.1585; val_edge_recon_loss: 739.4981; val_gene_expr_recon_loss: 25391.1709; val_lambda_latent_adj_recon_loss: 442.8381; val_lambda_latent_contrastive_instanceloss: 7.1387; val_lambda_latent_contrastive_clusterloss: 2.8057; val_gene_expr_mmd_loss: 17800.4932; val_global_loss: 43690.6055; val_optim_loss: 43690.6055
Epoch 24/100 |████----------------| 24.0% val_auroc_score: 0.9425; val_auprc_score: 0.9253; val_best_acc_score: 0.8304; val_best_f1_score: 0.8542; train_kl_reg_loss: 61.3425; train_edge_recon_loss: 1120.8641; train_gene_expr_recon_loss: 24886.4471; train_lambda_latent_adj_recon_loss: 673.7446; train_lambda_latent_contrastive_instanceloss: 7.4468; train_lambda_latent_contrastive_clusterloss: 3.1280; train_gene_expr_mmd_loss: 9225.8774; train_global_loss: 34857.9862; train_optim_loss: 34857.9862; val_kl_reg_loss: 46.2897; val_edge_recon_loss: 740.0579; val_gene_expr_recon_loss: 25554.2324; val_lambda_latent_adj_recon_loss: 439.0533; val_lambda_latent_contrastive_instanceloss: 7.1435; val_lambda_latent_contrastive_clusterloss: 2.8010; val_gene_expr_mmd_loss: 14800.4043; val_global_loss: 40849.9238; val_optim_loss: 40849.9238
Epoch 25/100 |█████---------------| 25.0% val_auroc_score: 0.9419; val_auprc_score: 0.9224; val_best_acc_score: 0.8366; val_best_f1_score: 0.8588; train_kl_reg_loss: 61.0323; train_edge_recon_loss: 1121.3521; train_gene_expr_recon_loss: 25007.5140; train_lambda_latent_adj_recon_loss: 651.6342; train_lambda_latent_contrastive_instanceloss: 7.4652; train_lambda_latent_contrastive_clusterloss: 3.1348; train_gene_expr_mmd_loss: 9686.4783; train_global_loss: 35417.2589; train_optim_loss: 35417.2589; val_kl_reg_loss: 46.0986; val_edge_recon_loss: 739.5158; val_gene_expr_recon_loss: 25008.1191; val_lambda_latent_adj_recon_loss: 430.5089; val_lambda_latent_contrastive_instanceloss: 7.1778; val_lambda_latent_contrastive_clusterloss: 2.8345; val_gene_expr_mmd_loss: 13443.3491; val_global_loss: 38938.0898; val_optim_loss: 38938.0898
Epoch 26/100 |█████---------------| 26.0% val_auroc_score: 0.9400; val_auprc_score: 0.9188; val_best_acc_score: 0.8228; val_best_f1_score: 0.8486; train_kl_reg_loss: 61.2733; train_edge_recon_loss: 1121.9922; train_gene_expr_recon_loss: 24751.6958; train_lambda_latent_adj_recon_loss: 652.3815; train_lambda_latent_contrastive_instanceloss: 7.4519; train_lambda_latent_contrastive_clusterloss: 3.1305; train_gene_expr_mmd_loss: 10052.9939; train_global_loss: 35528.9279; train_optim_loss: 35528.9279; val_kl_reg_loss: 46.0006; val_edge_recon_loss: 739.5542; val_gene_expr_recon_loss: 25374.7871; val_lambda_latent_adj_recon_loss: 426.7318; val_lambda_latent_contrastive_instanceloss: 7.1687; val_lambda_latent_contrastive_clusterloss: 2.8225; val_gene_expr_mmd_loss: 14191.8970; val_global_loss: 40049.4082; val_optim_loss: 40049.4082
Epoch 27/100 |█████---------------| 27.0% val_auroc_score: 0.9384; val_auprc_score: 0.9176; val_best_acc_score: 0.8293; val_best_f1_score: 0.8534; train_kl_reg_loss: 61.4528; train_edge_recon_loss: 1121.2838; train_gene_expr_recon_loss: 24980.0664; train_lambda_latent_adj_recon_loss: 651.1077; train_lambda_latent_contrastive_instanceloss: 7.4663; train_lambda_latent_contrastive_clusterloss: 3.1300; train_gene_expr_mmd_loss: 9384.7128; train_global_loss: 35087.9361; train_optim_loss: 35087.9361; val_kl_reg_loss: 46.9616; val_edge_recon_loss: 739.6445; val_gene_expr_recon_loss: 24845.7012; val_lambda_latent_adj_recon_loss: 436.9640; val_lambda_latent_contrastive_instanceloss: 7.1760; val_lambda_latent_contrastive_clusterloss: 2.8130; val_gene_expr_mmd_loss: 14986.8003; val_global_loss: 40326.4160; val_optim_loss: 40326.4160
Epoch 28/100 |█████---------------| 28.0% val_auroc_score: 0.9362; val_auprc_score: 0.9131; val_best_acc_score: 0.8221; val_best_f1_score: 0.8482; train_kl_reg_loss: 62.3724; train_edge_recon_loss: 1122.5048; train_gene_expr_recon_loss: 24954.5732; train_lambda_latent_adj_recon_loss: 660.5395; train_lambda_latent_contrastive_instanceloss: 7.4630; train_lambda_latent_contrastive_clusterloss: 3.1291; train_gene_expr_mmd_loss: 8719.0893; train_global_loss: 34407.1665; train_optim_loss: 34407.1665; val_kl_reg_loss: 47.5290; val_edge_recon_loss: 740.3092; val_gene_expr_recon_loss: 24930.5928; val_lambda_latent_adj_recon_loss: 440.3269; val_lambda_latent_contrastive_instanceloss: 7.2076; val_lambda_latent_contrastive_clusterloss: 2.8481; val_gene_expr_mmd_loss: 15718.4087; val_global_loss: 41146.9141; val_optim_loss: 41146.9141
Epoch 29/100 |█████---------------| 29.0% val_auroc_score: 0.9396; val_auprc_score: 0.9172; val_best_acc_score: 0.8242; val_best_f1_score: 0.8497; train_kl_reg_loss: 63.1409; train_edge_recon_loss: 1123.7300; train_gene_expr_recon_loss: 24739.8152; train_lambda_latent_adj_recon_loss: 665.2165; train_lambda_latent_contrastive_instanceloss: 7.4481; train_lambda_latent_contrastive_clusterloss: 3.1150; train_gene_expr_mmd_loss: 8983.0024; train_global_loss: 34461.7376; train_optim_loss: 34461.7376; val_kl_reg_loss: 48.2242; val_edge_recon_loss: 740.6504; val_gene_expr_recon_loss: 26006.6084; val_lambda_latent_adj_recon_loss: 445.4245; val_lambda_latent_contrastive_instanceloss: 7.1556; val_lambda_latent_contrastive_clusterloss: 2.7888; val_gene_expr_mmd_loss: 14666.8423; val_global_loss: 41177.0449; val_optim_loss: 41177.0449
Reducing learning rate: metric has not improved more than 0.0 in the last 4 epochs.
New learning rate is 1e-05.
Epoch 30/100 |██████--------------| 30.0% val_auroc_score: 0.9416; val_auprc_score: 0.9241; val_best_acc_score: 0.8295; val_best_f1_score: 0.8536; train_kl_reg_loss: 63.5734; train_edge_recon_loss: 1123.9885; train_gene_expr_recon_loss: 24735.9943; train_lambda_latent_adj_recon_loss: 669.8966; train_lambda_latent_contrastive_instanceloss: 7.4492; train_lambda_latent_contrastive_clusterloss: 3.1035; train_gene_expr_mmd_loss: 10032.6321; train_global_loss: 35512.6491; train_optim_loss: 35512.6491; val_kl_reg_loss: 48.1383; val_edge_recon_loss: 739.8245; val_gene_expr_recon_loss: 24617.4189; val_lambda_latent_adj_recon_loss: 443.6673; val_lambda_latent_contrastive_instanceloss: 7.1772; val_lambda_latent_contrastive_clusterloss: 2.8223; val_gene_expr_mmd_loss: 15018.5459; val_global_loss: 40137.7695; val_optim_loss: 40137.7695
Epoch 31/100 |██████--------------| 31.0% val_auroc_score: 0.9364; val_auprc_score: 0.9134; val_best_acc_score: 0.8229; val_best_f1_score: 0.8488; train_kl_reg_loss: 63.6231; train_edge_recon_loss: 1123.6684; train_gene_expr_recon_loss: 24977.4817; train_lambda_latent_adj_recon_loss: 673.2179; train_lambda_latent_contrastive_instanceloss: 7.4444; train_lambda_latent_contrastive_clusterloss: 3.1110; train_gene_expr_mmd_loss: 9322.6851; train_global_loss: 35047.5625; train_optim_loss: 35047.5625; val_kl_reg_loss: 48.0878; val_edge_recon_loss: 740.3685; val_gene_expr_recon_loss: 25021.6797; val_lambda_latent_adj_recon_loss: 441.5710; val_lambda_latent_contrastive_instanceloss: 7.1422; val_lambda_latent_contrastive_clusterloss: 2.7947; val_gene_expr_mmd_loss: 13635.2695; val_global_loss: 39156.5449; val_optim_loss: 39156.5449
Epoch 32/100 |██████--------------| 32.0% val_auroc_score: 0.9387; val_auprc_score: 0.9193; val_best_acc_score: 0.8170; val_best_f1_score: 0.8446; train_kl_reg_loss: 63.5845; train_edge_recon_loss: 1124.3448; train_gene_expr_recon_loss: 24986.6726; train_lambda_latent_adj_recon_loss: 669.0599; train_lambda_latent_contrastive_instanceloss: 7.4395; train_lambda_latent_contrastive_clusterloss: 3.0962; train_gene_expr_mmd_loss: 9863.1535; train_global_loss: 35593.0057; train_optim_loss: 35593.0057; val_kl_reg_loss: 48.4412; val_edge_recon_loss: 740.6776; val_gene_expr_recon_loss: 25189.8525; val_lambda_latent_adj_recon_loss: 447.6775; val_lambda_latent_contrastive_instanceloss: 7.1643; val_lambda_latent_contrastive_clusterloss: 2.8024; val_gene_expr_mmd_loss: 16868.0322; val_global_loss: 42563.9688; val_optim_loss: 42563.9688
Epoch 33/100 |██████--------------| 33.0% val_auroc_score: 0.9387; val_auprc_score: 0.9201; val_best_acc_score: 0.8186; val_best_f1_score: 0.8457; train_kl_reg_loss: 63.4851; train_edge_recon_loss: 1124.4870; train_gene_expr_recon_loss: 24772.4368; train_lambda_latent_adj_recon_loss: 666.5757; train_lambda_latent_contrastive_instanceloss: 7.4479; train_lambda_latent_contrastive_clusterloss: 3.1110; train_gene_expr_mmd_loss: 9254.6556; train_global_loss: 34767.7120; train_optim_loss: 34767.7120; val_kl_reg_loss: 48.3889; val_edge_recon_loss: 740.6885; val_gene_expr_recon_loss: 25377.2559; val_lambda_latent_adj_recon_loss: 444.0520; val_lambda_latent_contrastive_instanceloss: 7.1604; val_lambda_latent_contrastive_clusterloss: 2.7930; val_gene_expr_mmd_loss: 13313.5918; val_global_loss: 39193.2441; val_optim_loss: 39193.2441
Stopping early: metric has not improved more than 0.0 in the last 8 epochs.
If the early stopping criterion is too strong, please instantiate it with different parameters in the train method.
Model training finished after 3 min 16 sec.
Using best model state, which was in epoch 25.
--- MODEL EVALUATION ---
val AUROC score: 0.9394
val AUPRC score: 0.9175
val best accuracy score: 0.8343
val best F1 score: 0.8571
val MSE score: 0.1264
[9]:
# Compute latent neighbor graph
latent_key = 'garfield_latent'
sc.pp.neighbors(model.adata,
use_rep=latent_key,
key_added=latent_key)
# Compute UMAP embedding
sc.tl.umap(model.adata,
neighbors_key=latent_key)
[10]:
sc.pl.umap(model.adata, color=['batch', 'celltype'], wspace=0.35, edges=False)
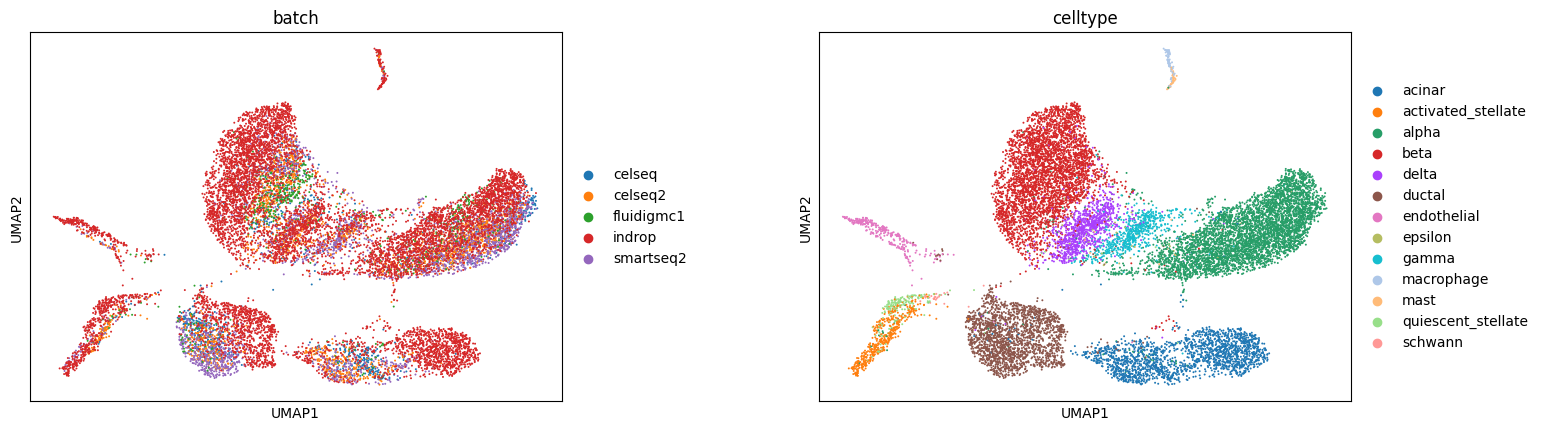
[11]:
sc.pl.umap(model.adata, color=['celltype'], wspace=0.35, edges=False, legend_loc='on data')

[12]:
# Save trained model
model_folder_path = f"{workdir}/model"
os.makedirs(model_folder_path, exist_ok=True)
model.save(dir_path=model_folder_path,
overwrite=True,
save_adata=True,
adata_file_name="adata_ref.h5ad")
Model saved successfully using pickle at /home/zhouweige/zhouwg_data/project/Garfield_tutorials/result/garfield_scRNA_panc/model/attr.pkl
[14]:
# load pre-trained model
model = Garfield.load(dir_path=model_folder_path,
adata_file_name="adata_ref.h5ad")
model
Model loaded successfully using pickle from /home/zhouweige/zhouwg_data/project/Garfield_tutorials/result/garfield_scRNA_panc/model/attr.pkl
AnnData object with n_obs × n_vars = 14890 × 3000
obs: 'ClusterID', 'ClusterName', 'batch', 'celltype', 'nCount_RNA', 'n_genes'
var: 'Selected', 'vst_mean', 'vst_variable', 'vst_variance', 'vst_variance_expected', 'vst_variance_standardized', 'n_cells', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'highly_variable_nbatches', 'highly_variable_intersection', 'mean', 'std'
uns: 'batch_colors', 'celltype_colors', 'garfield_latent', 'hvg', 'log1p', 'neighbors', 'pca', 'umap'
obsm: 'X_pca', 'X_umap', 'feat', 'garfield_latent', 'pca_cell_embeddings', 'umap_cell_embeddings'
varm: 'PCs', 'pca_feature_loadings'
layers: 'counts', 'norm_data', 'scale_data'
obsp: 'connectivities', 'distances', 'garfield_latent_connectivities', 'garfield_latent_distances'
--- DATA LOADING AND PREPROCESSING ---
COSINE SIM GRAPH DECODER -> dropout_rate: 0.2
[14]:
Garfield(
(model): GNNModelVAE(
(encoder): GATEncoder(
(layers): ModuleList(
(0): GATv2Conv(3000, 128, heads=3)
(1): GATv2Conv(384, 128, heads=3)
)
(norm_layers): ModuleList(
(0-1): 2 x BatchNorm1d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(conv_mean): GATv2Conv(384, 20, heads=3)
(conv_log_std): GATv2Conv(384, 20, heads=3)
)
(decoder): InnerProductDecoder()
(instance_projector): Sequential(
(0): Linear(in_features=20, out_features=20, bias=True)
(1): LayerNorm((20,), eps=1e-05, elementwise_affine=False)
(2): ReLU()
(3): Linear(in_features=20, out_features=3000, bias=True)
)
(cluster_projector): Sequential(
(0): Linear(in_features=20, out_features=20, bias=True)
(1): LayerNorm((20,), eps=1e-05, elementwise_affine=False)
(2): ReLU()
(3): Linear(in_features=20, out_features=20, bias=True)
(4): Softmax(dim=1)
)
(graph_decoder): CosineSimGraphDecoder(
(dropout): Dropout(p=0.2, inplace=False)
)
(adj_decoder): InnerProductDecoder()
(GAT_decoder): GATDecoder(
(layers): ModuleList(
(0): GATv2Conv(20, 128, heads=3)
(1): GATv2Conv(384, 128, heads=3)
)
(norm): ModuleList(
(0-1): 2 x None
)
(conv_recon): GATv2Conv(384, 3000, heads=3)
)
)
)
[ ]: