QueryToReference mapping
Here we will use human pancreas datasets (scRNA-seq data) of different studies as an example to illustrate how Garfield performs QueryToreference process.
[1]:
import os
os.chdir('/data2/zhouwg_data/project/Garfield')
os.getcwd()
[1]:
'/data2/zhouwg_data/project/Garfield'
[2]:
# load packages
import warnings
import Garfield as gf
import scanpy as sc
warnings.simplefilter(action="ignore", category=FutureWarning)
warnings.simplefilter(action='ignore', category=UserWarning)
gf.__version__
[2]:
'1.0.0'
[3]:
## load data
adata = sc.read_h5ad('/home/zhouweige/zhouwg_data/project/Garfield_tutorials/data/panc8.h5ad')
adata
[3]:
AnnData object with n_obs × n_vars = 14890 × 34363
obs: 'ClusterID', 'ClusterName', 'batch', 'celltype', 'nCount_RNA'
var: 'Selected', 'vst_mean', 'vst_variable', 'vst_variance', 'vst_variance_expected', 'vst_variance_standardized'
obsm: 'pca_cell_embeddings', 'umap_cell_embeddings'
varm: 'pca_feature_loadings'
layers: 'counts', 'norm_data', 'scale_data'
[4]:
# Ensure adata.X is counts.
adata.X.max()
[4]:
1453667.0
[5]:
# check the batch information of this dataset
adata.obs['batch'].value_counts()
[5]:
batch
indrop 8569
smartseq2 2394
celseq2 2285
celseq 1004
fluidigmc1 638
Name: count, dtype: int64
split all_adata into reference dataset and query dataset
[6]:
adata_ref = adata[~adata.obs['batch'].isin(['smartseq2', 'celseq2']),:].copy()
adata_ref
[6]:
AnnData object with n_obs × n_vars = 10211 × 34363
obs: 'ClusterID', 'ClusterName', 'batch', 'celltype', 'nCount_RNA'
var: 'Selected', 'vst_mean', 'vst_variable', 'vst_variance', 'vst_variance_expected', 'vst_variance_standardized'
obsm: 'pca_cell_embeddings', 'umap_cell_embeddings'
varm: 'pca_feature_loadings'
layers: 'counts', 'norm_data', 'scale_data'
[7]:
# Inspect the batches contained in the dataset.
adata_ref.obs.batch.value_counts()
[7]:
batch
indrop 8569
celseq 1004
fluidigmc1 638
Name: count, dtype: int64
[8]:
adata_query = adata[adata.obs['batch'].isin(['smartseq2', 'celseq2']),:].copy()
adata_query
[8]:
AnnData object with n_obs × n_vars = 4679 × 34363
obs: 'ClusterID', 'ClusterName', 'batch', 'celltype', 'nCount_RNA'
var: 'Selected', 'vst_mean', 'vst_variable', 'vst_variance', 'vst_variance_expected', 'vst_variance_standardized'
obsm: 'pca_cell_embeddings', 'umap_cell_embeddings'
varm: 'pca_feature_loadings'
layers: 'counts', 'norm_data', 'scale_data'
[9]:
# Inspect the batches contained in the dataset.
adata_query.obs.batch.value_counts()
[9]:
batch
smartseq2 2394
celseq2 2285
Name: count, dtype: int64
Integrating reference data using Garfield
For reference integration of scRNAseq data, we should adjust the following paremeters, and all parameter introductions can be found in Garfield_Model_Parameters.
[10]:
# set workdir
workdir = '/home/zhouweige/zhouwg_data/project/Garfield_tutorials/result/garfield_QueryToRef_panc'
gf.settings.set_workdir(workdir)
### modify parameter
user_config = dict(
## Input options
adata_list=adata,
profile='RNA', # if it is 'ATAC' or 'ADT', please adjust it.
sample_col='batch', # Specify columns for batch
## Preprocessing options
used_hvg=True,
min_cells=3,
min_features=0,
keep_mt=False,
target_sum=1e4,
rna_n_top_features=3000,
atac_n_top_features=None, # if data belongs to 'ATAC', please specify it.
n_components=50,
n_neighbors=5,
metric='euclidean', # STR Metric for clustering. Default is `euclidean`.
svd_solver='arpack',
# datasets
adj_key='connectivities',
# data split parameters
edge_val_ratio=0.1,
edge_test_ratio=0.,
node_val_ratio=0.1,
node_test_ratio=0.,
## Model options
augment_type='svd',
svd_q=5,
use_FCencoder=False,
conv_type='GATv2Conv', # GAT or GATv2Conv or GCN
gnn_layer=2,
hidden_dims=[128, 128],
bottle_neck_neurons=20,
cluster_num=20,
drop_feature_rate=0.2,
drop_edge_rate=0.2,
num_heads=3,
dropout=0.2,
concat=True,
used_edge_weight=False,
used_DSBN=False,
used_mmd=True,
# data loader parameters
num_neighbors=5,
loaders_n_hops=2,
edge_batch_size=4096,
node_batch_size=128, # None
# loss parameters
include_edge_recon_loss=True,
include_gene_expr_recon_loss=True,
lambda_latent_contrastive_instanceloss=1.0,
lambda_latent_contrastive_clusterloss=0.5,
lambda_gene_expr_recon=10., # To make the model more focused on learning expression features, increase this parameter.
lambda_edge_recon=1., # To make the model more focused on learning Adjacency graph features, increase this parameter.
lambda_latent_adj_recon_loss=1.,
lambda_omics_recon_mmd_loss=5., # If the integration is not strong enough, increase it.
# train parameters
n_epochs_no_edge_recon=0,
learning_rate=0.001,
weight_decay=1e-05,
gradient_clipping=5,
# other parameters
latent_key='garfield_latent',
reload_best_model=False,
use_early_stopping=True,
early_stopping_kwargs=None,
monitor=True,
seed=2024,
verbose=True
)
dict_config = gf.settings.set_gf_params(user_config)
Saving results in: /home/zhouweige/zhouwg_data/project/Garfield_tutorials/result/garfield_QueryToRef_panc
[11]:
from Garfield.model import Garfield
# Initialize model
model = Garfield(dict_config)
--- DATA LOADING AND PREPROCESSING ---
/home/zhouweige/anaconda3/envs/Garfield/lib/python3.9/site-packages/scipy/sparse/_index.py:143: SparseEfficiencyWarning: Changing the sparsity structure of a csr_matrix is expensive. lil_matrix is more efficient.
self._set_arrayXarray(i, j, x)
COSINE SIM GRAPH DECODER -> dropout_rate: 0.2
[12]:
# Train model
model.train()
--- INITIALIZING TRAINER ---
Using GPU: device-0
Number of training nodes: 13401
Number of validation nodes: 1489
Number of training edges: 41925
Number of validation edges: 4658
Edge batch size: 4096
Node batch size: 128
--- MODEL TRAINING ---
Epoch 1/100 |--------------------| 1.0% val_auroc_score: 0.9157; val_auprc_score: 0.9036; val_best_acc_score: 0.8301; val_best_f1_score: 0.8356; train_kl_reg_loss: 16.1825; train_edge_recon_loss: 1068.9525; train_gene_expr_recon_loss: 44175.5675; train_lambda_latent_adj_recon_loss: 545.4078; train_lambda_latent_contrastive_instanceloss: 7.1875; train_lambda_latent_contrastive_clusterloss: 3.6975; train_gene_expr_mmd_loss: 15203.5110; train_global_loss: 61020.5075; train_optim_loss: 61020.5075; val_kl_reg_loss: 10.3256; val_edge_recon_loss: 725.7085; val_gene_expr_recon_loss: 37283.7871; val_lambda_latent_adj_recon_loss: 323.4712; val_lambda_latent_contrastive_instanceloss: 7.1274; val_lambda_latent_contrastive_clusterloss: 3.6802; val_gene_expr_mmd_loss: 20023.7832; val_global_loss: 58377.8828; val_optim_loss: 58377.8828
Epoch 2/100 |--------------------| 2.0% val_auroc_score: 0.9160; val_auprc_score: 0.9018; val_best_acc_score: 0.8313; val_best_f1_score: 0.8303; train_kl_reg_loss: 14.0769; train_edge_recon_loss: 1068.7042; train_gene_expr_recon_loss: 36904.1690; train_lambda_latent_adj_recon_loss: 462.0126; train_lambda_latent_contrastive_instanceloss: 7.1844; train_lambda_latent_contrastive_clusterloss: 3.6740; train_gene_expr_mmd_loss: 13617.5485; train_global_loss: 52077.3686; train_optim_loss: 52077.3686; val_kl_reg_loss: 16.4489; val_edge_recon_loss: 714.5010; val_gene_expr_recon_loss: 33093.5732; val_lambda_latent_adj_recon_loss: 458.5562; val_lambda_latent_contrastive_instanceloss: 7.0902; val_lambda_latent_contrastive_clusterloss: 3.6856; val_gene_expr_mmd_loss: 19973.4590; val_global_loss: 54267.3125; val_optim_loss: 54267.3125
Epoch 3/100 |--------------------| 3.0% val_auroc_score: 0.9087; val_auprc_score: 0.8862; val_best_acc_score: 0.8288; val_best_f1_score: 0.8419; train_kl_reg_loss: 23.3235; train_edge_recon_loss: 1065.7232; train_gene_expr_recon_loss: 32321.7828; train_lambda_latent_adj_recon_loss: 663.6116; train_lambda_latent_contrastive_instanceloss: 7.1632; train_lambda_latent_contrastive_clusterloss: 3.6605; train_gene_expr_mmd_loss: 12735.9023; train_global_loss: 46821.1669; train_optim_loss: 46821.1669; val_kl_reg_loss: 18.5986; val_edge_recon_loss: 709.5734; val_gene_expr_recon_loss: 29878.9014; val_lambda_latent_adj_recon_loss: 488.6322; val_lambda_latent_contrastive_instanceloss: 7.0645; val_lambda_latent_contrastive_clusterloss: 3.6303; val_gene_expr_mmd_loss: 23385.5352; val_global_loss: 54491.9336; val_optim_loss: 54491.9336
Epoch 4/100 |--------------------| 4.0% val_auroc_score: 0.9154; val_auprc_score: 0.9013; val_best_acc_score: 0.8190; val_best_f1_score: 0.8388; train_kl_reg_loss: 22.4784; train_edge_recon_loss: 1065.1408; train_gene_expr_recon_loss: 30330.4984; train_lambda_latent_adj_recon_loss: 600.6782; train_lambda_latent_contrastive_instanceloss: 7.1399; train_lambda_latent_contrastive_clusterloss: 3.6471; train_gene_expr_mmd_loss: 13043.9889; train_global_loss: 45073.5721; train_optim_loss: 45073.5721; val_kl_reg_loss: 21.1735; val_edge_recon_loss: 709.0407; val_gene_expr_recon_loss: 28401.0664; val_lambda_latent_adj_recon_loss: 549.5345; val_lambda_latent_contrastive_instanceloss: 6.9729; val_lambda_latent_contrastive_clusterloss: 3.6093; val_gene_expr_mmd_loss: 19949.5049; val_global_loss: 49640.9023; val_optim_loss: 49640.9023
Epoch 5/100 |█-------------------| 5.0% val_auroc_score: 0.9188; val_auprc_score: 0.9039; val_best_acc_score: 0.8115; val_best_f1_score: 0.8369; train_kl_reg_loss: 28.9390; train_edge_recon_loss: 1075.7247; train_gene_expr_recon_loss: 29041.3667; train_lambda_latent_adj_recon_loss: 790.9314; train_lambda_latent_contrastive_instanceloss: 7.1121; train_lambda_latent_contrastive_clusterloss: 3.6335; train_gene_expr_mmd_loss: 13184.4371; train_global_loss: 44132.1449; train_optim_loss: 44132.1449; val_kl_reg_loss: 25.0177; val_edge_recon_loss: 718.1575; val_gene_expr_recon_loss: 26778.0205; val_lambda_latent_adj_recon_loss: 611.6943; val_lambda_latent_contrastive_instanceloss: 6.8188; val_lambda_latent_contrastive_clusterloss: 3.5727; val_gene_expr_mmd_loss: 22653.3271; val_global_loss: 50796.6074; val_optim_loss: 50796.6074
Epoch 6/100 |█-------------------| 6.0% val_auroc_score: 0.9300; val_auprc_score: 0.9076; val_best_acc_score: 0.8557; val_best_f1_score: 0.8715; train_kl_reg_loss: 32.6245; train_edge_recon_loss: 1078.5657; train_gene_expr_recon_loss: 28696.3517; train_lambda_latent_adj_recon_loss: 821.2750; train_lambda_latent_contrastive_instanceloss: 7.0544; train_lambda_latent_contrastive_clusterloss: 3.6230; train_gene_expr_mmd_loss: 11292.4105; train_global_loss: 41931.9048; train_optim_loss: 41931.9048; val_kl_reg_loss: 30.0431; val_edge_recon_loss: 718.5328; val_gene_expr_recon_loss: 26316.2480; val_lambda_latent_adj_recon_loss: 683.0103; val_lambda_latent_contrastive_instanceloss: 6.7069; val_lambda_latent_contrastive_clusterloss: 3.5205; val_gene_expr_mmd_loss: 31723.9150; val_global_loss: 59481.9785; val_optim_loss: 59481.9785
Epoch 7/100 |█-------------------| 7.0% val_auroc_score: 0.9440; val_auprc_score: 0.9248; val_best_acc_score: 0.8824; val_best_f1_score: 0.8932; train_kl_reg_loss: 38.4472; train_edge_recon_loss: 1087.4075; train_gene_expr_recon_loss: 27741.9785; train_lambda_latent_adj_recon_loss: 937.7711; train_lambda_latent_contrastive_instanceloss: 6.9949; train_lambda_latent_contrastive_clusterloss: 3.5905; train_gene_expr_mmd_loss: 12411.6596; train_global_loss: 42227.8484; train_optim_loss: 42227.8484; val_kl_reg_loss: 35.1383; val_edge_recon_loss: 721.9316; val_gene_expr_recon_loss: 26582.5449; val_lambda_latent_adj_recon_loss: 761.8015; val_lambda_latent_contrastive_instanceloss: 6.6289; val_lambda_latent_contrastive_clusterloss: 3.4640; val_gene_expr_mmd_loss: 17321.7402; val_global_loss: 45433.2480; val_optim_loss: 45433.2480
Epoch 8/100 |█-------------------| 8.0% val_auroc_score: 0.9301; val_auprc_score: 0.9008; val_best_acc_score: 0.8656; val_best_f1_score: 0.8804; train_kl_reg_loss: 42.6339; train_edge_recon_loss: 1092.2864; train_gene_expr_recon_loss: 27447.0314; train_lambda_latent_adj_recon_loss: 1000.0844; train_lambda_latent_contrastive_instanceloss: 6.9718; train_lambda_latent_contrastive_clusterloss: 3.5651; train_gene_expr_mmd_loss: 12645.8888; train_global_loss: 42238.4613; train_optim_loss: 42238.4613; val_kl_reg_loss: 35.5052; val_edge_recon_loss: 728.0549; val_gene_expr_recon_loss: 25172.6562; val_lambda_latent_adj_recon_loss: 709.0105; val_lambda_latent_contrastive_instanceloss: 6.6711; val_lambda_latent_contrastive_clusterloss: 3.4232; val_gene_expr_mmd_loss: 16955.4995; val_global_loss: 43610.8203; val_optim_loss: 43610.8203
Epoch 9/100 |█-------------------| 9.0% val_auroc_score: 0.9425; val_auprc_score: 0.9226; val_best_acc_score: 0.8670; val_best_f1_score: 0.8819; train_kl_reg_loss: 44.3019; train_edge_recon_loss: 1098.9832; train_gene_expr_recon_loss: 26745.1584; train_lambda_latent_adj_recon_loss: 978.9788; train_lambda_latent_contrastive_instanceloss: 6.9415; train_lambda_latent_contrastive_clusterloss: 3.5365; train_gene_expr_mmd_loss: 11462.6558; train_global_loss: 40340.5561; train_optim_loss: 40340.5561; val_kl_reg_loss: 36.7074; val_edge_recon_loss: 731.6920; val_gene_expr_recon_loss: 25611.9551; val_lambda_latent_adj_recon_loss: 677.2860; val_lambda_latent_contrastive_instanceloss: 6.6314; val_lambda_latent_contrastive_clusterloss: 3.3303; val_gene_expr_mmd_loss: 18257.6025; val_global_loss: 45325.2051; val_optim_loss: 45325.2051
Epoch 10/100 |██------------------| 10.0% val_auroc_score: 0.9352; val_auprc_score: 0.9170; val_best_acc_score: 0.8551; val_best_f1_score: 0.8724; train_kl_reg_loss: 44.8827; train_edge_recon_loss: 1098.7575; train_gene_expr_recon_loss: 26496.0955; train_lambda_latent_adj_recon_loss: 874.3268; train_lambda_latent_contrastive_instanceloss: 6.9263; train_lambda_latent_contrastive_clusterloss: 3.5026; train_gene_expr_mmd_loss: 11650.6394; train_global_loss: 40175.1307; train_optim_loss: 40175.1307; val_kl_reg_loss: 38.3149; val_edge_recon_loss: 730.1173; val_gene_expr_recon_loss: 25049.7373; val_lambda_latent_adj_recon_loss: 648.6267; val_lambda_latent_contrastive_instanceloss: 6.5630; val_lambda_latent_contrastive_clusterloss: 3.2741; val_gene_expr_mmd_loss: 14484.5996; val_global_loss: 40961.2344; val_optim_loss: 40961.2344
Epoch 11/100 |██------------------| 11.0% val_auroc_score: 0.9463; val_auprc_score: 0.9320; val_best_acc_score: 0.8498; val_best_f1_score: 0.8687; train_kl_reg_loss: 48.6772; train_edge_recon_loss: 1104.3418; train_gene_expr_recon_loss: 25477.8668; train_lambda_latent_adj_recon_loss: 913.4525; train_lambda_latent_contrastive_instanceloss: 6.8921; train_lambda_latent_contrastive_clusterloss: 3.4664; train_gene_expr_mmd_loss: 11730.1613; train_global_loss: 39284.8580; train_optim_loss: 39284.8580; val_kl_reg_loss: 40.0142; val_edge_recon_loss: 734.4434; val_gene_expr_recon_loss: 25709.5723; val_lambda_latent_adj_recon_loss: 638.1149; val_lambda_latent_contrastive_instanceloss: 6.5825; val_lambda_latent_contrastive_clusterloss: 3.2438; val_gene_expr_mmd_loss: 18829.5332; val_global_loss: 45961.5020; val_optim_loss: 45961.5020
Epoch 12/100 |██------------------| 12.0% val_auroc_score: 0.9378; val_auprc_score: 0.9182; val_best_acc_score: 0.8550; val_best_f1_score: 0.8724; train_kl_reg_loss: 47.7212; train_edge_recon_loss: 1103.2801; train_gene_expr_recon_loss: 26274.2315; train_lambda_latent_adj_recon_loss: 794.7153; train_lambda_latent_contrastive_instanceloss: 6.8901; train_lambda_latent_contrastive_clusterloss: 3.4454; train_gene_expr_mmd_loss: 10785.7312; train_global_loss: 39016.0149; train_optim_loss: 39016.0149; val_kl_reg_loss: 38.6589; val_edge_recon_loss: 733.7630; val_gene_expr_recon_loss: 24606.8955; val_lambda_latent_adj_recon_loss: 547.6250; val_lambda_latent_contrastive_instanceloss: 6.5071; val_lambda_latent_contrastive_clusterloss: 3.1592; val_gene_expr_mmd_loss: 12596.5967; val_global_loss: 38533.2051; val_optim_loss: 38533.2051
Epoch 13/100 |██------------------| 13.0% val_auroc_score: 0.9399; val_auprc_score: 0.9221; val_best_acc_score: 0.8586; val_best_f1_score: 0.8753; train_kl_reg_loss: 49.7788; train_edge_recon_loss: 1103.5075; train_gene_expr_recon_loss: 25498.3732; train_lambda_latent_adj_recon_loss: 749.1411; train_lambda_latent_contrastive_instanceloss: 6.8575; train_lambda_latent_contrastive_clusterloss: 3.3920; train_gene_expr_mmd_loss: 10068.7101; train_global_loss: 37479.7603; train_optim_loss: 37479.7603; val_kl_reg_loss: 42.5903; val_edge_recon_loss: 731.7270; val_gene_expr_recon_loss: 23778.8867; val_lambda_latent_adj_recon_loss: 567.2588; val_lambda_latent_contrastive_instanceloss: 6.5426; val_lambda_latent_contrastive_clusterloss: 3.1768; val_gene_expr_mmd_loss: 13347.9219; val_global_loss: 38478.1055; val_optim_loss: 38478.1055
Epoch 14/100 |██------------------| 14.0% val_auroc_score: 0.9367; val_auprc_score: 0.9153; val_best_acc_score: 0.8526; val_best_f1_score: 0.8703; train_kl_reg_loss: 53.3784; train_edge_recon_loss: 1106.2284; train_gene_expr_recon_loss: 25454.3224; train_lambda_latent_adj_recon_loss: 745.5509; train_lambda_latent_contrastive_instanceloss: 6.8332; train_lambda_latent_contrastive_clusterloss: 3.3433; train_gene_expr_mmd_loss: 11686.1863; train_global_loss: 39055.8427; train_optim_loss: 39055.8427; val_kl_reg_loss: 43.6329; val_edge_recon_loss: 733.3530; val_gene_expr_recon_loss: 25487.7031; val_lambda_latent_adj_recon_loss: 534.8989; val_lambda_latent_contrastive_instanceloss: 6.4724; val_lambda_latent_contrastive_clusterloss: 3.0385; val_gene_expr_mmd_loss: 15254.1089; val_global_loss: 42063.2051; val_optim_loss: 42063.2051
Epoch 15/100 |███-----------------| 15.0% val_auroc_score: 0.9342; val_auprc_score: 0.9117; val_best_acc_score: 0.8651; val_best_f1_score: 0.8796; train_kl_reg_loss: 52.2410; train_edge_recon_loss: 1105.2799; train_gene_expr_recon_loss: 26243.8338; train_lambda_latent_adj_recon_loss: 645.8846; train_lambda_latent_contrastive_instanceloss: 6.8395; train_lambda_latent_contrastive_clusterloss: 3.3252; train_gene_expr_mmd_loss: 10467.6909; train_global_loss: 38525.0952; train_optim_loss: 38525.0952; val_kl_reg_loss: 43.4548; val_edge_recon_loss: 728.7201; val_gene_expr_recon_loss: 24245.8525; val_lambda_latent_adj_recon_loss: 484.7950; val_lambda_latent_contrastive_instanceloss: 6.4627; val_lambda_latent_contrastive_clusterloss: 3.0142; val_gene_expr_mmd_loss: 18792.2568; val_global_loss: 44304.5566; val_optim_loss: 44304.5566
Epoch 16/100 |███-----------------| 16.0% val_auroc_score: 0.9394; val_auprc_score: 0.9178; val_best_acc_score: 0.8632; val_best_f1_score: 0.8787; train_kl_reg_loss: 53.2228; train_edge_recon_loss: 1105.3957; train_gene_expr_recon_loss: 25766.1195; train_lambda_latent_adj_recon_loss: 612.8635; train_lambda_latent_contrastive_instanceloss: 6.8335; train_lambda_latent_contrastive_clusterloss: 3.2967; train_gene_expr_mmd_loss: 10419.9617; train_global_loss: 37967.6935; train_optim_loss: 37967.6935; val_kl_reg_loss: 44.8001; val_edge_recon_loss: 733.5848; val_gene_expr_recon_loss: 24905.3594; val_lambda_latent_adj_recon_loss: 458.9157; val_lambda_latent_contrastive_instanceloss: 6.4977; val_lambda_latent_contrastive_clusterloss: 3.0116; val_gene_expr_mmd_loss: 15658.3604; val_global_loss: 41810.5273; val_optim_loss: 41810.5273
Epoch 17/100 |███-----------------| 17.0% val_auroc_score: 0.9382; val_auprc_score: 0.9144; val_best_acc_score: 0.8478; val_best_f1_score: 0.8667; train_kl_reg_loss: 56.5201; train_edge_recon_loss: 1109.0488; train_gene_expr_recon_loss: 25138.3888; train_lambda_latent_adj_recon_loss: 623.3008; train_lambda_latent_contrastive_instanceloss: 6.8080; train_lambda_latent_contrastive_clusterloss: 3.2434; train_gene_expr_mmd_loss: 11567.1858; train_global_loss: 38504.4954; train_optim_loss: 38504.4954; val_kl_reg_loss: 43.9962; val_edge_recon_loss: 731.8570; val_gene_expr_recon_loss: 25024.0830; val_lambda_latent_adj_recon_loss: 416.9788; val_lambda_latent_contrastive_instanceloss: 6.5487; val_lambda_latent_contrastive_clusterloss: 2.9510; val_gene_expr_mmd_loss: 18470.1909; val_global_loss: 44696.6055; val_optim_loss: 44696.6055
Reducing learning rate: metric has not improved more than 0.0 in the last 4 epochs.
New learning rate is 0.0001.
Epoch 18/100 |███-----------------| 18.0% val_auroc_score: 0.9399; val_auprc_score: 0.9210; val_best_acc_score: 0.8590; val_best_f1_score: 0.8753; train_kl_reg_loss: 55.9439; train_edge_recon_loss: 1109.1010; train_gene_expr_recon_loss: 25372.1209; train_lambda_latent_adj_recon_loss: 582.5874; train_lambda_latent_contrastive_instanceloss: 6.8161; train_lambda_latent_contrastive_clusterloss: 3.2229; train_gene_expr_mmd_loss: 11044.3298; train_global_loss: 38174.1229; train_optim_loss: 38174.1229; val_kl_reg_loss: 45.0803; val_edge_recon_loss: 732.8819; val_gene_expr_recon_loss: 24814.0654; val_lambda_latent_adj_recon_loss: 431.3822; val_lambda_latent_contrastive_instanceloss: 6.5143; val_lambda_latent_contrastive_clusterloss: 2.9305; val_gene_expr_mmd_loss: 12592.3154; val_global_loss: 38625.1699; val_optim_loss: 38625.1699
Epoch 19/100 |███-----------------| 19.0% val_auroc_score: 0.9453; val_auprc_score: 0.9260; val_best_acc_score: 0.8597; val_best_f1_score: 0.8760; train_kl_reg_loss: 57.5698; train_edge_recon_loss: 1110.6684; train_gene_expr_recon_loss: 25772.2349; train_lambda_latent_adj_recon_loss: 607.6233; train_lambda_latent_contrastive_instanceloss: 6.7968; train_lambda_latent_contrastive_clusterloss: 3.2041; train_gene_expr_mmd_loss: 10282.9408; train_global_loss: 37841.0376; train_optim_loss: 37841.0376; val_kl_reg_loss: 45.6293; val_edge_recon_loss: 734.2554; val_gene_expr_recon_loss: 24948.3203; val_lambda_latent_adj_recon_loss: 433.3168; val_lambda_latent_contrastive_instanceloss: 6.5048; val_lambda_latent_contrastive_clusterloss: 2.9224; val_gene_expr_mmd_loss: 14224.9688; val_global_loss: 40395.9180; val_optim_loss: 40395.9180
Epoch 20/100 |████----------------| 20.0% val_auroc_score: 0.9429; val_auprc_score: 0.9247; val_best_acc_score: 0.8569; val_best_f1_score: 0.8739; train_kl_reg_loss: 58.3979; train_edge_recon_loss: 1112.7159; train_gene_expr_recon_loss: 25315.4125; train_lambda_latent_adj_recon_loss: 615.7094; train_lambda_latent_contrastive_instanceloss: 6.8068; train_lambda_latent_contrastive_clusterloss: 3.2193; train_gene_expr_mmd_loss: 9921.9230; train_global_loss: 37034.1847; train_optim_loss: 37034.1847; val_kl_reg_loss: 46.1690; val_edge_recon_loss: 734.2748; val_gene_expr_recon_loss: 25229.2207; val_lambda_latent_adj_recon_loss: 431.7146; val_lambda_latent_contrastive_instanceloss: 6.4481; val_lambda_latent_contrastive_clusterloss: 2.8819; val_gene_expr_mmd_loss: 15751.4712; val_global_loss: 42202.1797; val_optim_loss: 42202.1797
Epoch 21/100 |████----------------| 21.0% val_auroc_score: 0.9426; val_auprc_score: 0.9250; val_best_acc_score: 0.8553; val_best_f1_score: 0.8727; train_kl_reg_loss: 58.9426; train_edge_recon_loss: 1113.9752; train_gene_expr_recon_loss: 24940.3658; train_lambda_latent_adj_recon_loss: 618.2378; train_lambda_latent_contrastive_instanceloss: 6.7961; train_lambda_latent_contrastive_clusterloss: 3.1909; train_gene_expr_mmd_loss: 8696.6983; train_global_loss: 35438.2070; train_optim_loss: 35438.2070; val_kl_reg_loss: 46.8090; val_edge_recon_loss: 735.0276; val_gene_expr_recon_loss: 25058.0127; val_lambda_latent_adj_recon_loss: 435.4973; val_lambda_latent_contrastive_instanceloss: 6.4694; val_lambda_latent_contrastive_clusterloss: 2.8939; val_gene_expr_mmd_loss: 12439.1631; val_global_loss: 38723.8750; val_optim_loss: 38723.8750
Stopping early: metric has not improved more than 0.0 in the last 8 epochs.
If the early stopping criterion is too strong, please instantiate it with different parameters in the train method.
Model training finished after 1 min 26 sec.
--- MODEL EVALUATION ---
val AUROC score: 0.9415
val AUPRC score: 0.9226
val best accuracy score: 0.8553
val best F1 score: 0.8727
val MSE score: 0.1235
[13]:
# Compute latent neighbor graph
latent_key = 'garfield_latent'
sc.pp.neighbors(model.adata,
use_rep=latent_key,
key_added=latent_key)
# Compute UMAP embedding
sc.tl.umap(model.adata,
neighbors_key=latent_key)
[14]:
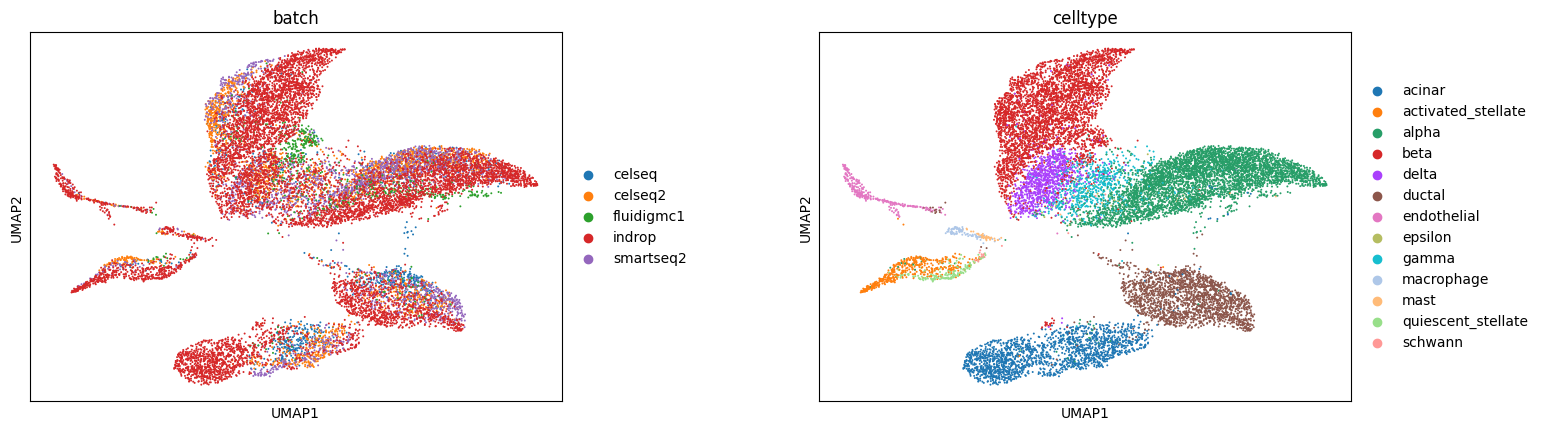
sc.pl.umap(model.adata, color=['batch', 'celltype'], wspace=0.35, edges=False)
[15]:
# Save trained model
model_folder_path = f"{workdir}/model"
os.makedirs(model_folder_path, exist_ok=True)
model.save(dir_path=model_folder_path,
overwrite=True,
save_adata=True,
adata_file_name="adata_ref.h5ad")
Model saved successfully using pickle at /home/zhouweige/zhouwg_data/project/Garfield_tutorials/result/garfield_QueryToRef_panc/model/attr.pkl
[ ]:
# load pre-trained model(optional)
model_folder_path = f"{workdir}/model"
model = Garfield.load(dir_path=model_folder_path,
adata_file_name="adata_ref.h5ad")
Perform surgery on reference model and fine-tune on query dataset
[16]:
# load_query_data
new_model = model.load_query_data(dir_path=model_folder_path,
query_adata=adata_query,
ref_adata_name="adata_ref.h5ad",
batch_key='batch',
use_cuda=True,
unfreeze_all_weights=False,
unfreeze_eps_weight=True,
unfreeze_layer0=True,
used_mmd=True)
# Training and obtain latent representation
new_model.train()
WARNING:Garfield.model.utils:WARNING: Query shares 8.7303% of its genes with the reference.This may lead to inaccuracy in the results.
Query data contains expression data of 31363 genes that were not contained in the reference dataset. This information will be removed from the query data object for further processing.
AnnData object with n_obs × n_vars = 4679 × 3000
obs: 'ClusterID', 'ClusterName', 'batch', 'celltype', 'nCount_RNA'
var: 'Selected', 'vst_mean', 'vst_variable', 'vst_variance', 'vst_variance_expected', 'vst_variance_standardized'
obsm: 'pca_cell_embeddings', 'umap_cell_embeddings'
varm: 'pca_feature_loadings'
layers: 'counts', 'norm_data', 'scale_data'
Model loaded successfully using pickle from /home/zhouweige/zhouwg_data/project/Garfield_tutorials/result/garfield_QueryToRef_panc/model/attr.pkl
--- DATA LOADING AND PREPROCESSING ---
/home/zhouweige/anaconda3/envs/Garfield/lib/python3.9/site-packages/scipy/sparse/_index.py:143: SparseEfficiencyWarning: Changing the sparsity structure of a csr_matrix is expensive. lil_matrix is more efficient.
self._set_arrayXarray(i, j, x)
COSINE SIM GRAPH DECODER -> dropout_rate: 0.2
--- INITIALIZING TRAINER ---
Using GPU: device-0
Number of training nodes: 17612
Number of validation nodes: 1957
Number of training edges: 50961
Number of validation edges: 5662
Edge batch size: 4096
Node batch size: 128
--- MODEL TRAINING ---
Epoch 1/100 |--------------------| 1.0% val_auroc_score: 0.9378; val_auprc_score: 0.9223; val_best_acc_score: 0.8601; val_best_f1_score: 0.8750; train_kl_reg_loss: 90.2840; train_edge_recon_loss: 1161.4314; train_gene_expr_recon_loss: 68683.3224; train_lambda_latent_adj_recon_loss: 1358.0003; train_lambda_latent_contrastive_instanceloss: 6.6684; train_lambda_latent_contrastive_clusterloss: 3.1175; train_gene_expr_mmd_loss: 23785.2812; train_global_loss: 95088.1046; train_optim_loss: 95088.1046; val_kl_reg_loss: 66.4380; val_edge_recon_loss: 887.9496; val_gene_expr_recon_loss: 68764.3203; val_lambda_latent_adj_recon_loss: 738.4747; val_lambda_latent_contrastive_instanceloss: 6.4927; val_lambda_latent_contrastive_clusterloss: 2.9303; val_gene_expr_mmd_loss: 28299.4463; val_global_loss: 98766.0508; val_optim_loss: 98766.0508
Epoch 2/100 |--------------------| 2.0% val_auroc_score: 0.9390; val_auprc_score: 0.9248; val_best_acc_score: 0.8659; val_best_f1_score: 0.8798; train_kl_reg_loss: 88.2911; train_edge_recon_loss: 1158.0677; train_gene_expr_recon_loss: 66539.7064; train_lambda_latent_adj_recon_loss: 1251.3568; train_lambda_latent_contrastive_instanceloss: 6.6541; train_lambda_latent_contrastive_clusterloss: 3.0853; train_gene_expr_mmd_loss: 20582.3794; train_global_loss: 89629.5421; train_optim_loss: 89629.5421; val_kl_reg_loss: 68.0751; val_edge_recon_loss: 889.2206; val_gene_expr_recon_loss: 67699.5664; val_lambda_latent_adj_recon_loss: 742.3927; val_lambda_latent_contrastive_instanceloss: 6.4212; val_lambda_latent_contrastive_clusterloss: 2.8544; val_gene_expr_mmd_loss: 32615.8643; val_global_loss: 102024.3945; val_optim_loss: 102024.3945
Epoch 3/100 |--------------------| 3.0% val_auroc_score: 0.9420; val_auprc_score: 0.9264; val_best_acc_score: 0.8799; val_best_f1_score: 0.8903; train_kl_reg_loss: 83.0066; train_edge_recon_loss: 1154.2347; train_gene_expr_recon_loss: 64765.3101; train_lambda_latent_adj_recon_loss: 1041.6884; train_lambda_latent_contrastive_instanceloss: 6.6581; train_lambda_latent_contrastive_clusterloss: 3.0933; train_gene_expr_mmd_loss: 22177.8685; train_global_loss: 89231.8618; train_optim_loss: 89231.8618; val_kl_reg_loss: 66.0341; val_edge_recon_loss: 884.6854; val_gene_expr_recon_loss: 64257.1973; val_lambda_latent_adj_recon_loss: 665.8507; val_lambda_latent_contrastive_instanceloss: 6.4506; val_lambda_latent_contrastive_clusterloss: 2.9087; val_gene_expr_mmd_loss: 22926.6689; val_global_loss: 88809.7969; val_optim_loss: 88809.7969
Epoch 4/100 |--------------------| 4.0% val_auroc_score: 0.9394; val_auprc_score: 0.9236; val_best_acc_score: 0.8686; val_best_f1_score: 0.8814; train_kl_reg_loss: 85.0633; train_edge_recon_loss: 1154.4986; train_gene_expr_recon_loss: 66554.4195; train_lambda_latent_adj_recon_loss: 1061.0528; train_lambda_latent_contrastive_instanceloss: 6.6373; train_lambda_latent_contrastive_clusterloss: 3.0845; train_gene_expr_mmd_loss: 25538.5813; train_global_loss: 94403.3359; train_optim_loss: 94403.3359; val_kl_reg_loss: 67.3140; val_edge_recon_loss: 887.7297; val_gene_expr_recon_loss: 67715.3789; val_lambda_latent_adj_recon_loss: 677.1403; val_lambda_latent_contrastive_instanceloss: 6.4508; val_lambda_latent_contrastive_clusterloss: 2.9158; val_gene_expr_mmd_loss: 18271.6021; val_global_loss: 87628.5352; val_optim_loss: 87628.5352
Epoch 5/100 |█-------------------| 5.0% val_auroc_score: 0.9392; val_auprc_score: 0.9214; val_best_acc_score: 0.8669; val_best_f1_score: 0.8801; train_kl_reg_loss: 86.9500; train_edge_recon_loss: 1156.9940; train_gene_expr_recon_loss: 65350.6770; train_lambda_latent_adj_recon_loss: 1050.8077; train_lambda_latent_contrastive_instanceloss: 6.6364; train_lambda_latent_contrastive_clusterloss: 3.0956; train_gene_expr_mmd_loss: 18672.2621; train_global_loss: 86327.4231; train_optim_loss: 86327.4231; val_kl_reg_loss: 69.3743; val_edge_recon_loss: 890.1452; val_gene_expr_recon_loss: 69141.0625; val_lambda_latent_adj_recon_loss: 670.2768; val_lambda_latent_contrastive_instanceloss: 6.4136; val_lambda_latent_contrastive_clusterloss: 2.8776; val_gene_expr_mmd_loss: 29368.3564; val_global_loss: 100148.5039; val_optim_loss: 100148.5039
Epoch 6/100 |█-------------------| 6.0% val_auroc_score: 0.9423; val_auprc_score: 0.9287; val_best_acc_score: 0.8703; val_best_f1_score: 0.8828; train_kl_reg_loss: 88.8486; train_edge_recon_loss: 1157.0062; train_gene_expr_recon_loss: 66171.7695; train_lambda_latent_adj_recon_loss: 1027.9607; train_lambda_latent_contrastive_instanceloss: 6.6387; train_lambda_latent_contrastive_clusterloss: 3.0928; train_gene_expr_mmd_loss: 18009.0334; train_global_loss: 86464.3486; train_optim_loss: 86464.3486; val_kl_reg_loss: 73.0540; val_edge_recon_loss: 889.3134; val_gene_expr_recon_loss: 66627.9492; val_lambda_latent_adj_recon_loss: 701.4525; val_lambda_latent_contrastive_instanceloss: 6.4109; val_lambda_latent_contrastive_clusterloss: 2.8832; val_gene_expr_mmd_loss: 20260.6211; val_global_loss: 88561.6797; val_optim_loss: 88561.6797
Epoch 7/100 |█-------------------| 7.0% val_auroc_score: 0.9431; val_auprc_score: 0.9294; val_best_acc_score: 0.8761; val_best_f1_score: 0.8874; train_kl_reg_loss: 89.3563; train_edge_recon_loss: 1158.0861; train_gene_expr_recon_loss: 66343.6923; train_lambda_latent_adj_recon_loss: 997.6345; train_lambda_latent_contrastive_instanceloss: 6.6476; train_lambda_latent_contrastive_clusterloss: 3.1030; train_gene_expr_mmd_loss: 17570.0494; train_global_loss: 86168.5715; train_optim_loss: 86168.5715; val_kl_reg_loss: 73.4756; val_edge_recon_loss: 887.8884; val_gene_expr_recon_loss: 64782.8535; val_lambda_latent_adj_recon_loss: 687.4509; val_lambda_latent_contrastive_instanceloss: 6.4417; val_lambda_latent_contrastive_clusterloss: 2.9325; val_gene_expr_mmd_loss: 23301.4736; val_global_loss: 89742.5195; val_optim_loss: 89742.5195
Epoch 8/100 |█-------------------| 8.0% val_auroc_score: 0.9433; val_auprc_score: 0.9287; val_best_acc_score: 0.8805; val_best_f1_score: 0.8900; train_kl_reg_loss: 93.3262; train_edge_recon_loss: 1159.1723; train_gene_expr_recon_loss: 65959.1809; train_lambda_latent_adj_recon_loss: 1071.8946; train_lambda_latent_contrastive_instanceloss: 6.6429; train_lambda_latent_contrastive_clusterloss: 3.0937; train_gene_expr_mmd_loss: 30030.6154; train_global_loss: 98323.9249; train_optim_loss: 98323.9249; val_kl_reg_loss: 68.8630; val_edge_recon_loss: 888.5204; val_gene_expr_recon_loss: 68780.3555; val_lambda_latent_adj_recon_loss: 607.1150; val_lambda_latent_contrastive_instanceloss: 6.4429; val_lambda_latent_contrastive_clusterloss: 2.9375; val_gene_expr_mmd_loss: 28193.7031; val_global_loss: 98547.9336; val_optim_loss: 98547.9336
Reducing learning rate: metric has not improved more than 0.0 in the last 4 epochs.
New learning rate is 0.0001.
Epoch 9/100 |█-------------------| 9.0% val_auroc_score: 0.9429; val_auprc_score: 0.9276; val_best_acc_score: 0.8825; val_best_f1_score: 0.8917; train_kl_reg_loss: 87.1182; train_edge_recon_loss: 1156.4912; train_gene_expr_recon_loss: 64946.6779; train_lambda_latent_adj_recon_loss: 919.7955; train_lambda_latent_contrastive_instanceloss: 6.6498; train_lambda_latent_contrastive_clusterloss: 3.0950; train_gene_expr_mmd_loss: 19565.2604; train_global_loss: 86685.0895; train_optim_loss: 86685.0895; val_kl_reg_loss: 68.8177; val_edge_recon_loss: 887.6615; val_gene_expr_recon_loss: 64963.8594; val_lambda_latent_adj_recon_loss: 600.3480; val_lambda_latent_contrastive_instanceloss: 6.4170; val_lambda_latent_contrastive_clusterloss: 2.8780; val_gene_expr_mmd_loss: 30405.9082; val_global_loss: 96935.8906; val_optim_loss: 96935.8906
Epoch 10/100 |██------------------| 10.0% val_auroc_score: 0.9429; val_auprc_score: 0.9275; val_best_acc_score: 0.8826; val_best_f1_score: 0.8918; train_kl_reg_loss: 87.5277; train_edge_recon_loss: 1156.1979; train_gene_expr_recon_loss: 65122.8696; train_lambda_latent_adj_recon_loss: 915.0496; train_lambda_latent_contrastive_instanceloss: 6.6500; train_lambda_latent_contrastive_clusterloss: 3.0966; train_gene_expr_mmd_loss: 16295.4086; train_global_loss: 83586.8023; train_optim_loss: 83586.8023; val_kl_reg_loss: 69.4626; val_edge_recon_loss: 887.2529; val_gene_expr_recon_loss: 64801.9707; val_lambda_latent_adj_recon_loss: 607.8253; val_lambda_latent_contrastive_instanceloss: 6.4159; val_lambda_latent_contrastive_clusterloss: 2.8678; val_gene_expr_mmd_loss: 22496.2910; val_global_loss: 88872.0859; val_optim_loss: 88872.0859
Epoch 11/100 |██------------------| 11.0% val_auroc_score: 0.9410; val_auprc_score: 0.9243; val_best_acc_score: 0.8819; val_best_f1_score: 0.8912; train_kl_reg_loss: 87.6680; train_edge_recon_loss: 1156.6623; train_gene_expr_recon_loss: 65522.8002; train_lambda_latent_adj_recon_loss: 904.4707; train_lambda_latent_contrastive_instanceloss: 6.6559; train_lambda_latent_contrastive_clusterloss: 3.1035; train_gene_expr_mmd_loss: 16687.0730; train_global_loss: 84368.4333; train_optim_loss: 84368.4333; val_kl_reg_loss: 69.2649; val_edge_recon_loss: 886.2350; val_gene_expr_recon_loss: 64695.0234; val_lambda_latent_adj_recon_loss: 601.4301; val_lambda_latent_contrastive_instanceloss: 6.4337; val_lambda_latent_contrastive_clusterloss: 2.9089; val_gene_expr_mmd_loss: 34927.3428; val_global_loss: 101188.6406; val_optim_loss: 101188.6406
Epoch 12/100 |██------------------| 12.0% val_auroc_score: 0.9434; val_auprc_score: 0.9276; val_best_acc_score: 0.8823; val_best_f1_score: 0.8913; train_kl_reg_loss: 87.1668; train_edge_recon_loss: 1155.7526; train_gene_expr_recon_loss: 65091.4630; train_lambda_latent_adj_recon_loss: 893.1087; train_lambda_latent_contrastive_instanceloss: 6.6447; train_lambda_latent_contrastive_clusterloss: 3.0865; train_gene_expr_mmd_loss: 16417.7948; train_global_loss: 83655.0168; train_optim_loss: 83655.0168; val_kl_reg_loss: 67.2080; val_edge_recon_loss: 886.4709; val_gene_expr_recon_loss: 65559.4961; val_lambda_latent_adj_recon_loss: 564.5641; val_lambda_latent_contrastive_instanceloss: 6.4242; val_lambda_latent_contrastive_clusterloss: 2.9024; val_gene_expr_mmd_loss: 21494.4932; val_global_loss: 88581.5664; val_optim_loss: 88581.5664
Stopping early: metric has not improved more than 0.0 in the last 8 epochs.
If the early stopping criterion is too strong, please instantiate it with different parameters in the train method.
Model training finished after 1 min 2 sec.
--- MODEL EVALUATION ---
val AUROC score: 0.9422
val AUPRC score: 0.9281
val best accuracy score: 0.8783
val best F1 score: 0.8881
val MSE score: 0.3336
[17]:
# plot UMAP
sc.pp.neighbors(new_model.adata, use_rep='garfield_latent')
sc.tl.umap(new_model.adata)
sc.pl.umap(new_model.adata, color=['projection', 'celltype'],
ncols=1, wspace=0.20, edges=False)

[18]:
## split
adata_ref = new_model.adata[new_model.adata.obs['projection'] == 'reference', :]
adata_query = new_model.adata[new_model.adata.obs['projection'] == 'query', :]
Label transfer
[19]:
### Label transfer
## major celltype
adata_query = new_model.label_transfer(ref_adata=adata_ref,
ref_adata_emb='garfield_latent',
query_adata=adata_query,
query_adata_emb='garfield_latent',
n_neighbors=10,
ref_adata_obs=adata_ref.obs,
label_keys='celltype')
adata_query
Weighted KNN with n_neighbors = 10 ...
Label transfer finished!
[19]:
AnnData object with n_obs × n_vars = 4679 × 3000
obs: 'ClusterID', 'ClusterName', 'batch', 'celltype', 'nCount_RNA', 'n_genes', 'projection', 'transferred_celltype_unfiltered', 'transferred_celltype_uncert'
var: 'n_cells', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'highly_variable_nbatches', 'highly_variable_intersection', 'mean', 'std'
uns: 'log1p', 'hvg', 'pca', 'neighbors', 'umap', 'projection_colors', 'celltype_colors'
obsm: 'X_pca', 'X_umap', 'feat', 'pca_cell_embeddings', 'umap_cell_embeddings', 'garfield_latent'
varm: 'PCs'
layers: 'counts', 'norm_data', 'scale_data'
obsp: 'distances', 'connectivities'
[20]:
## predicted label
sc.pl.umap(adata_query,color=['transferred_celltype_unfiltered'])

[21]:
## real label
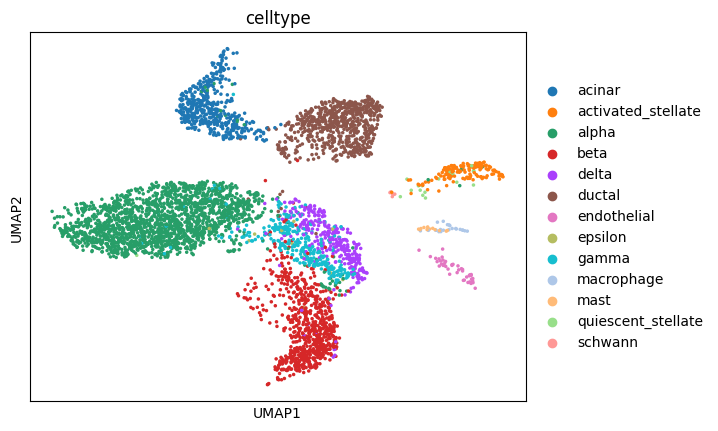
sc.pl.umap(adata_query,color=['celltype'])
[22]:
import pandas as pd
pd.crosstab(adata_query.obs.celltype, adata_query.obs.transferred_celltype_unfiltered)
[22]:
| transferred_celltype_unfiltered | acinar | activated_stellate | alpha | beta | delta | ductal | endothelial | epsilon | gamma | macrophage | mast | quiescent_stellate | schwann |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| celltype | |||||||||||||
| acinar | 461 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| activated_stellate | 0 | 143 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| alpha | 11 | 5 | 1817 | 8 | 4 | 0 | 0 | 0 | 7 | 0 | 0 | 0 | 0 |
| beta | 0 | 0 | 0 | 742 | 8 | 1 | 0 | 0 | 2 | 0 | 0 | 0 | 0 |
| delta | 0 | 0 | 3 | 15 | 304 | 0 | 0 | 0 | 8 | 0 | 0 | 0 | 0 |
| ductal | 1 | 0 | 1 | 1 | 1 | 696 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| endothelial | 0 | 0 | 0 | 0 | 0 | 0 | 42 | 0 | 0 | 0 | 0 | 0 | 0 |
| epsilon | 0 | 0 | 1 | 1 | 3 | 0 | 0 | 2 | 5 | 0 | 0 | 0 | 0 |
| gamma | 1 | 0 | 18 | 0 | 29 | 0 | 0 | 0 | 275 | 0 | 0 | 0 | 0 |
| macrophage | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 22 | 0 | 0 | 0 |
| mast | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 2 | 10 | 0 | 0 |
| quiescent_stellate | 0 | 9 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 7 | 0 |
| schwann | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 6 |
[23]:
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
import numpy as np
cm = confusion_matrix(adata_query.obs.celltype, adata_query.obs.transferred_celltype_unfiltered)
ConfusionMatrixDisplay(
confusion_matrix=np.round((cm.T/np.sum(cm, axis=1)).T*100),
display_labels=np.unique(adata_query.obs.celltype)
).plot()
[23]:
<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x7fd159f324c0>

[24]:
# Save trained model
model.save(dir_path=model_folder_path,
overwrite=True,
save_adata=True,
adata_file_name="adata_concat.h5ad")
Model saved successfully using pickle at /home/zhouweige/zhouwg_data/project/Garfield_tutorials/result/garfield_QueryToRef_panc/model/attr.pkl
[ ]: